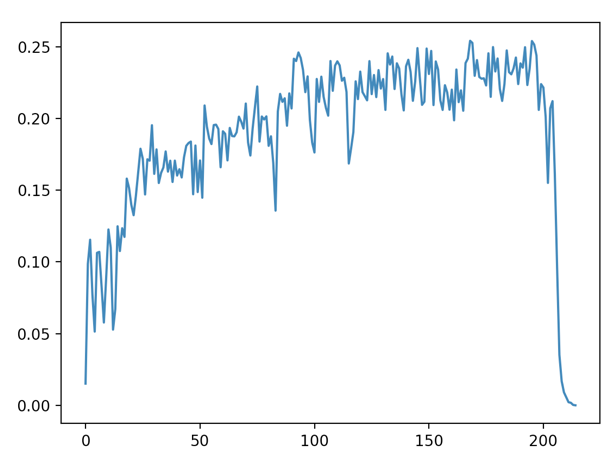
이번 사운드 클라우드 클로닝 프로젝트에서 가장 핵심 기능 중에 하나였던, 오디오 파형을 그려내는 것에 대하여 포스팅을 하겠습니다.
librosa , FFmpeg(리브로사 쓸 때에 꼭 필요합니다.)
1. Audio의 Raw Data를 Librosa 라이브러리를 이용해서 추출 해냅니다. 추출할때에는 모노로 추출해냅니다.
2. 추출한 데이터의 음원의 길이를 알려고 하면, 전체 바이트수/sampling_rate를 하면 초를 알 수 있습니다.
3. 그러면 1초당 데이터들의 평균값을 내면, 초당 막대 한개의 데이터를 구해낼 수 있습니다.
4. 추출해낸 데이터를 원하는 방식으로 정규화 및 가공을 합니다.(저는 딱히 가공을 하진 않았고 프론트에서 사용하기 좋은 데이터로 재가공 했습니다.)
5. 그 데이터를 다시 Data를 다시 text 및 data 파일로 저장합니다.
다른 라이브러리들도 많습니다. pydub이 가장 유명한걸로 알고 있는데, 제가 모자란 탓인지 리브로사를 썼을때, 제가 원하는 데이터를 짧은 시간내에 구해내기가 쉬웠고, 제가 원했던 모양으로 잘 나왔습니다. 오디오 전문가가 아닌 저는 여기가 한계가 아닐까 생각합니다.
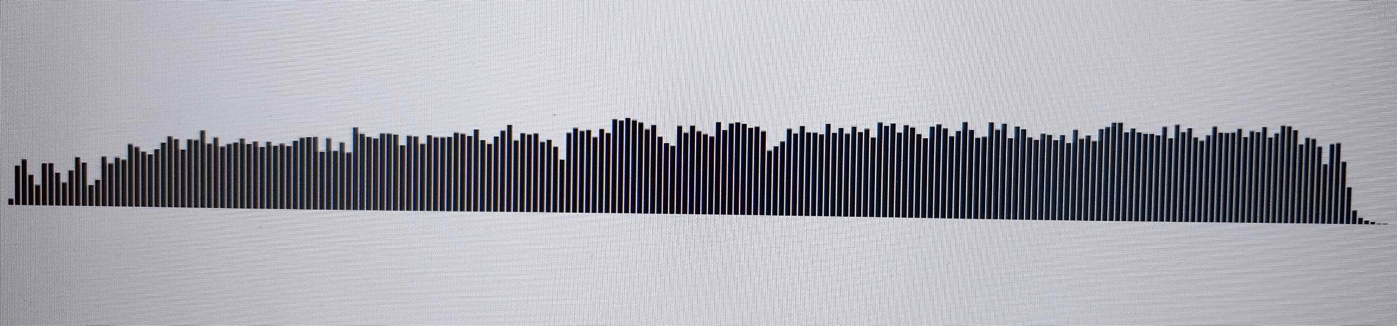
위 사진은 해당 데이터를 이용해서 자바스크립트의 캔버스를 이용해서 그린 그림입니다.
def audio_analysis(self,path,name):
audio, sampling_rate = librosa.load(path,mono=True)
sum = 0
count = 0
arr = []
blocks = 270
one_block_data = int(len(audio)/270)
w = open(path+".txt",'w')
for element in audio:
count+=1
sum+=abs(element)
if(count>=one_block_data):
data = int(round(((sum)/one_block_data),3)*300)
arr.append(data)
count = 0
sum = 0
w.write(str(data)+"\\\\n")
print(arr)
w.close()